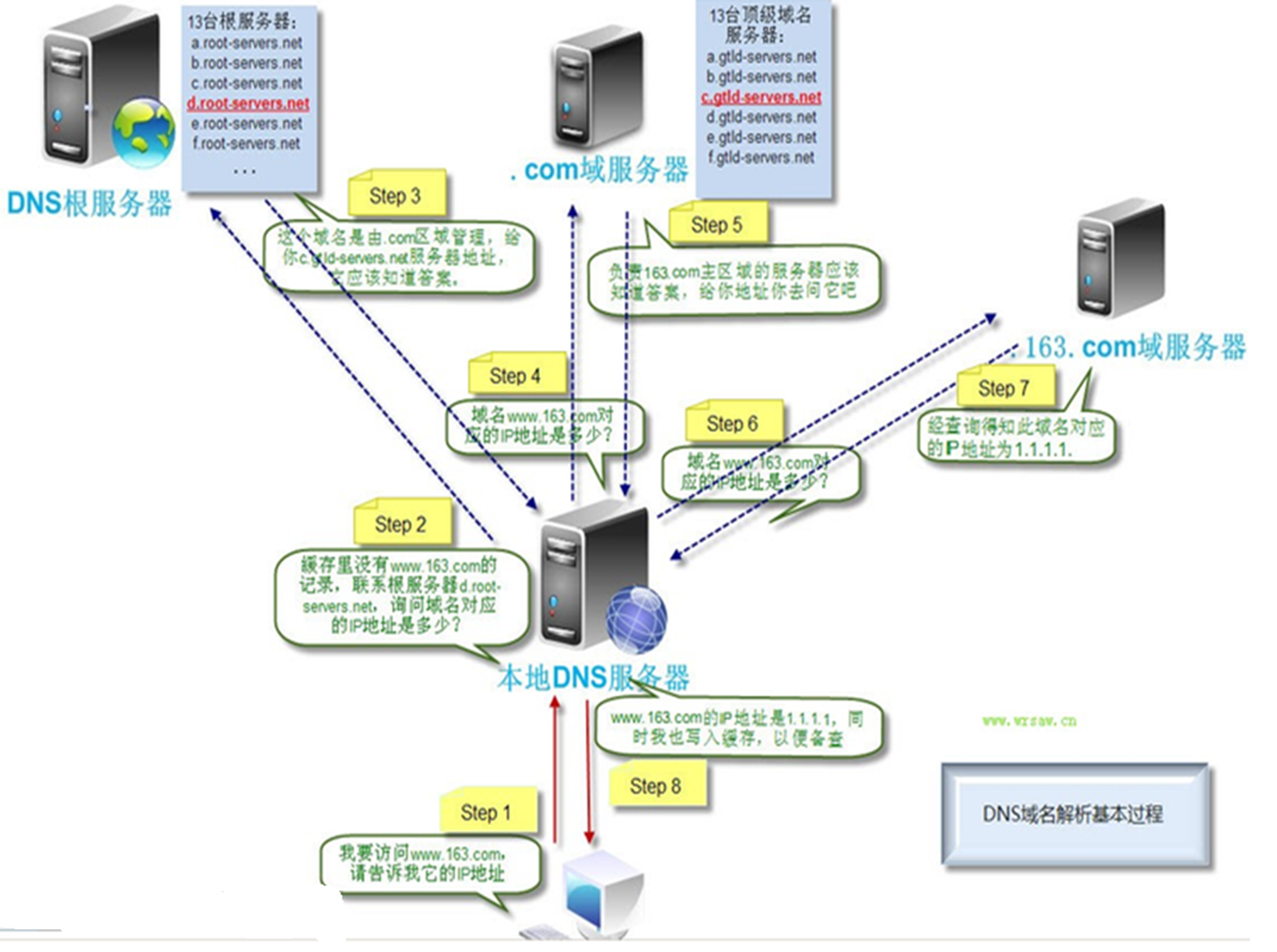
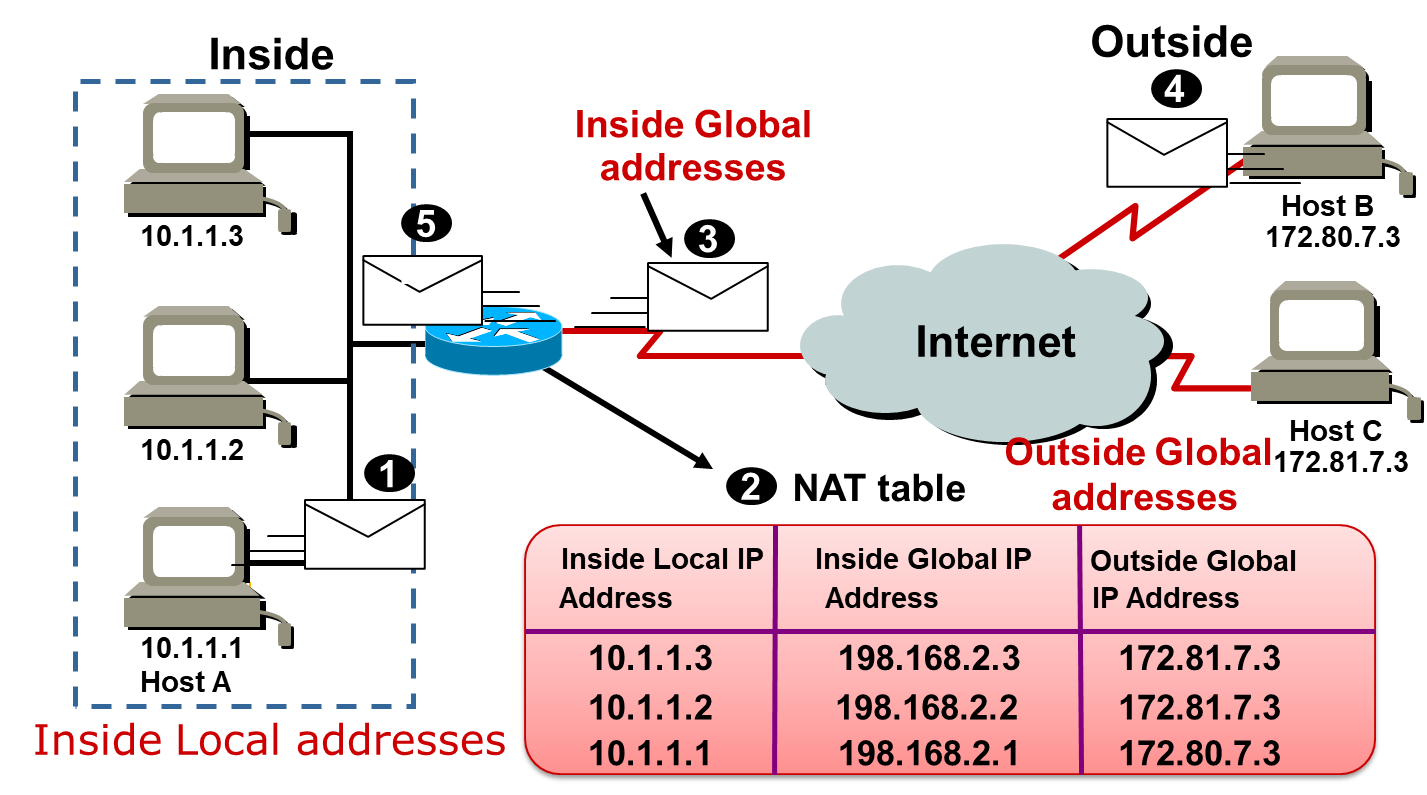
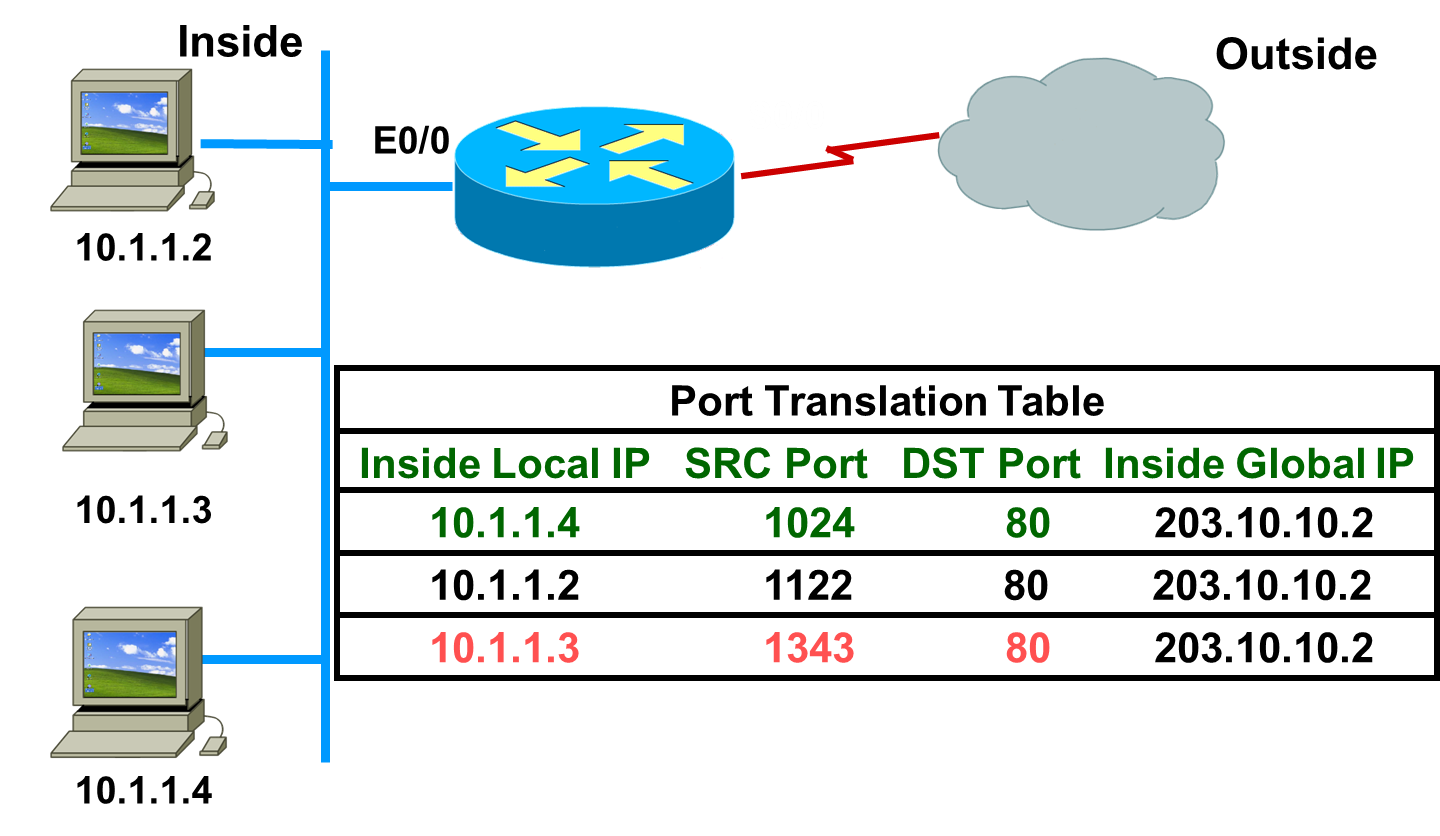
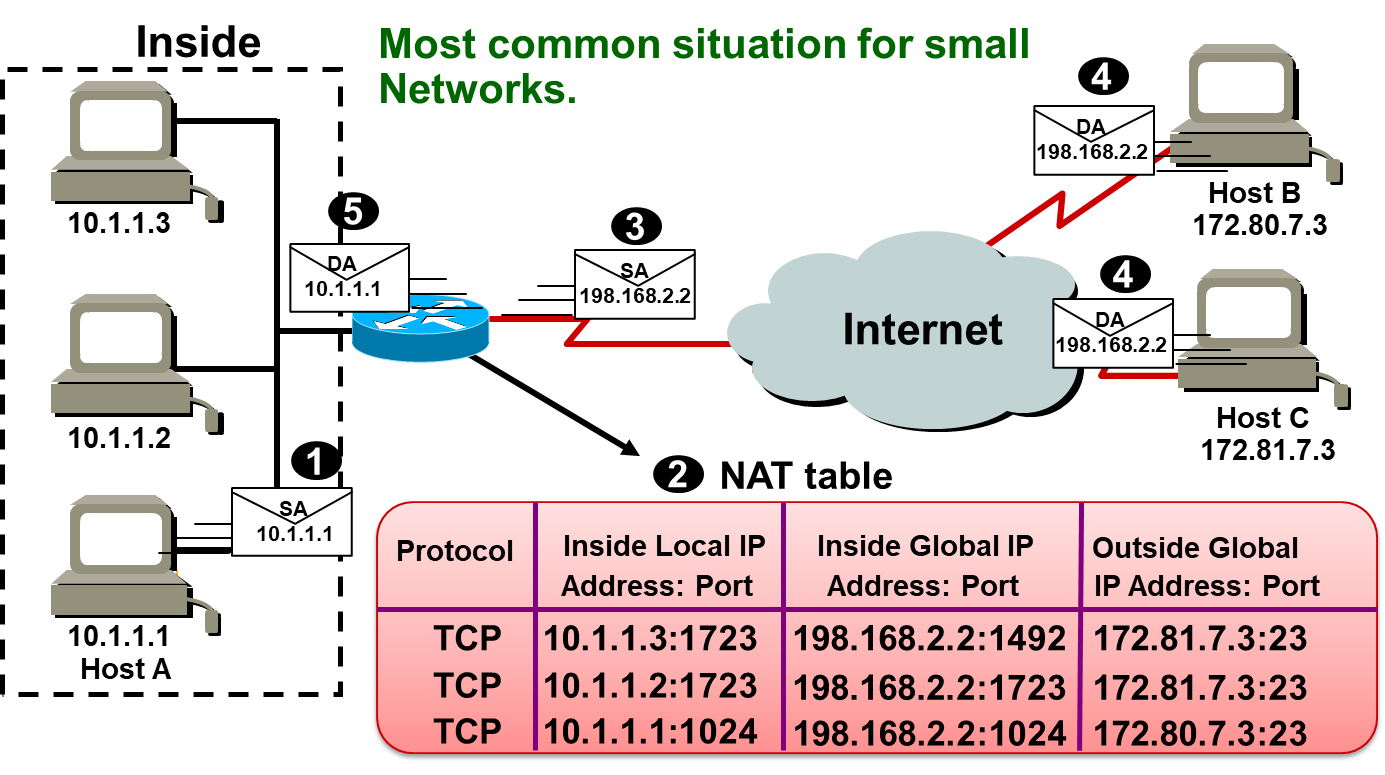
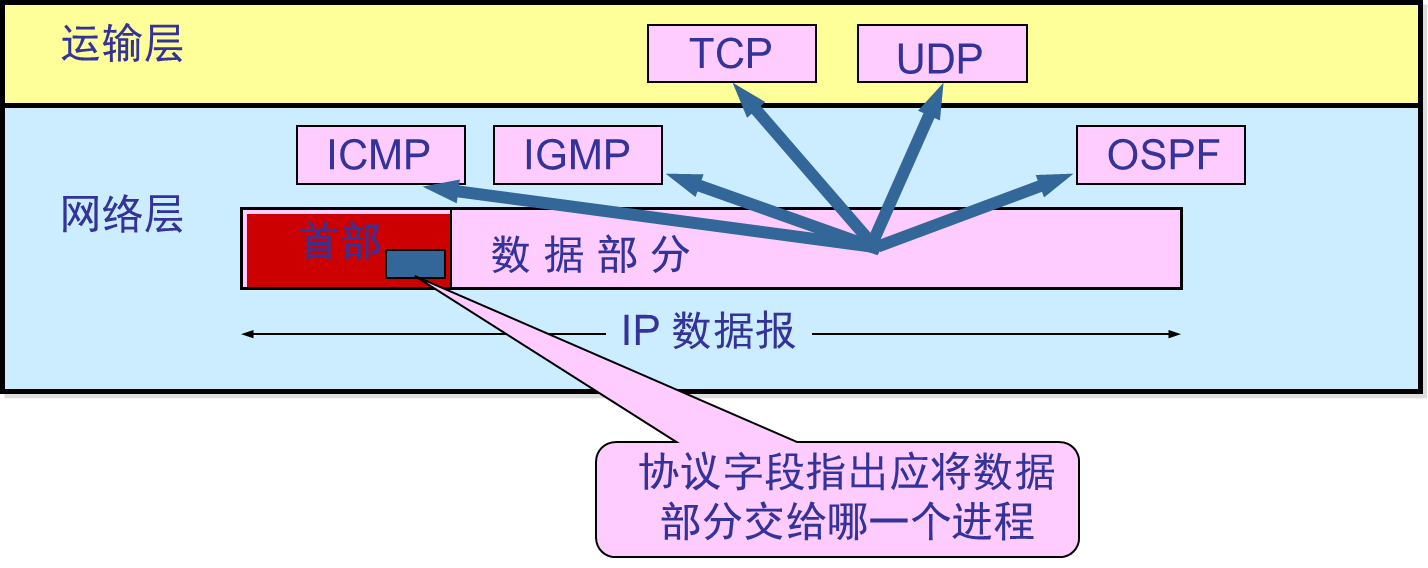
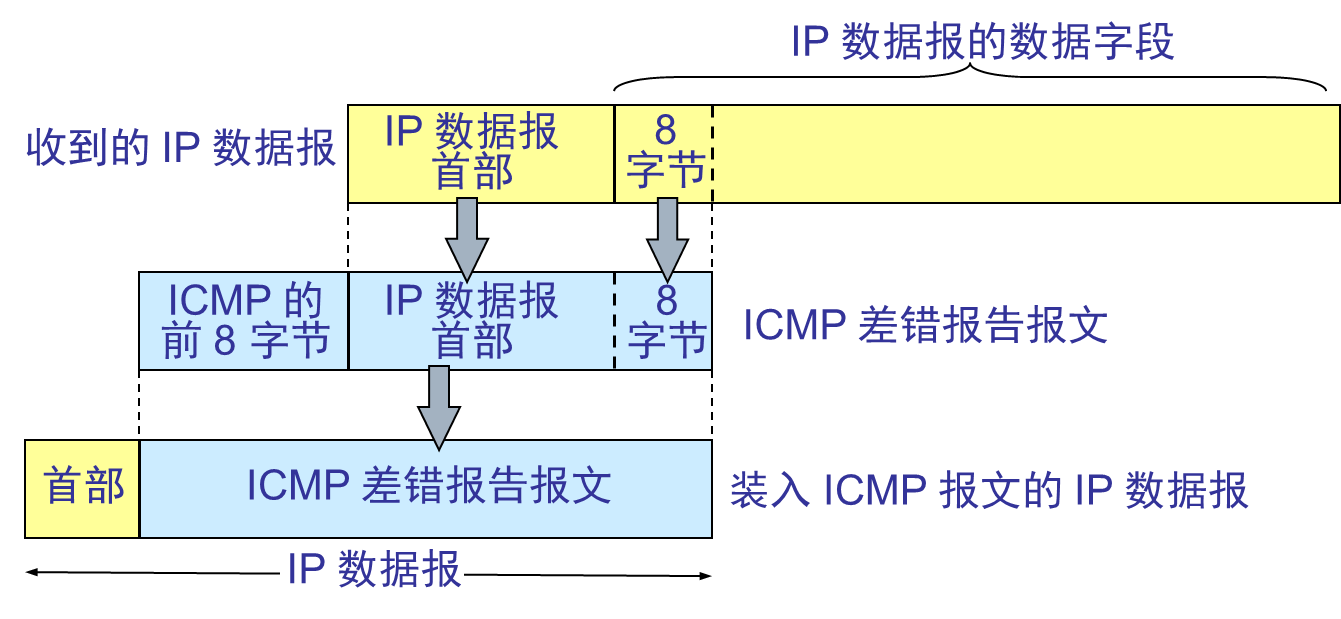
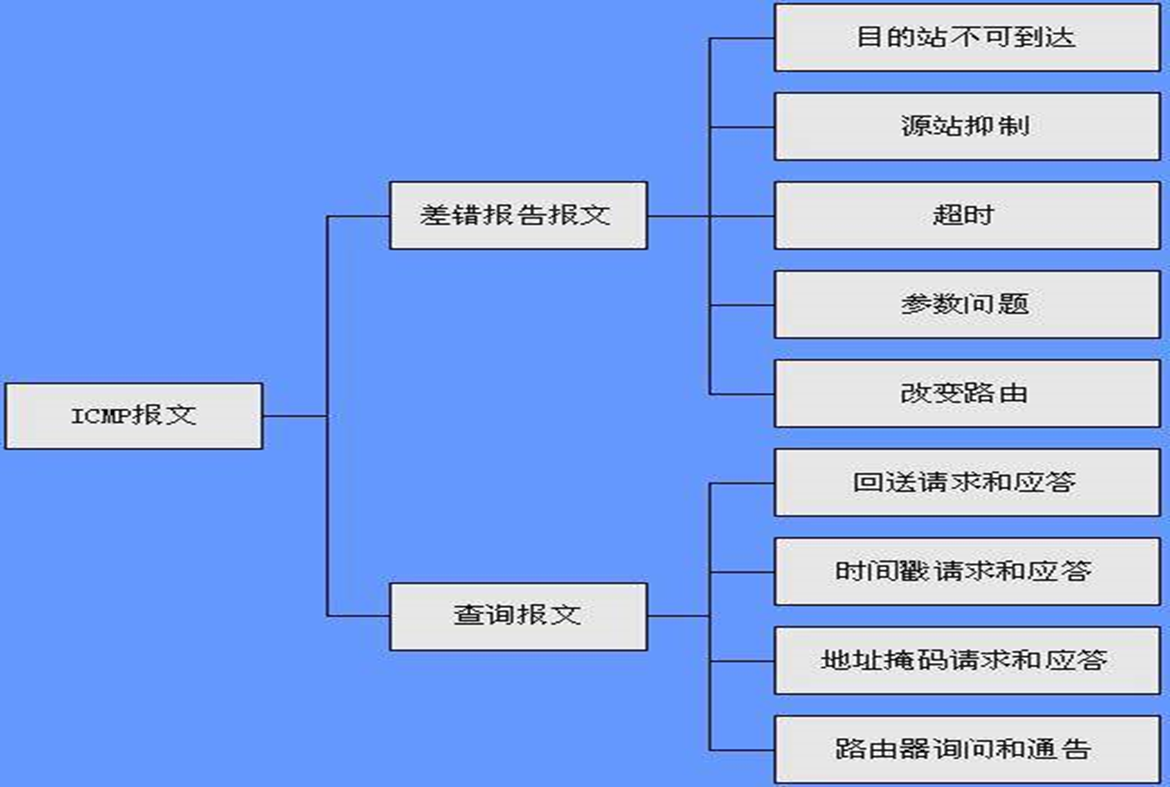
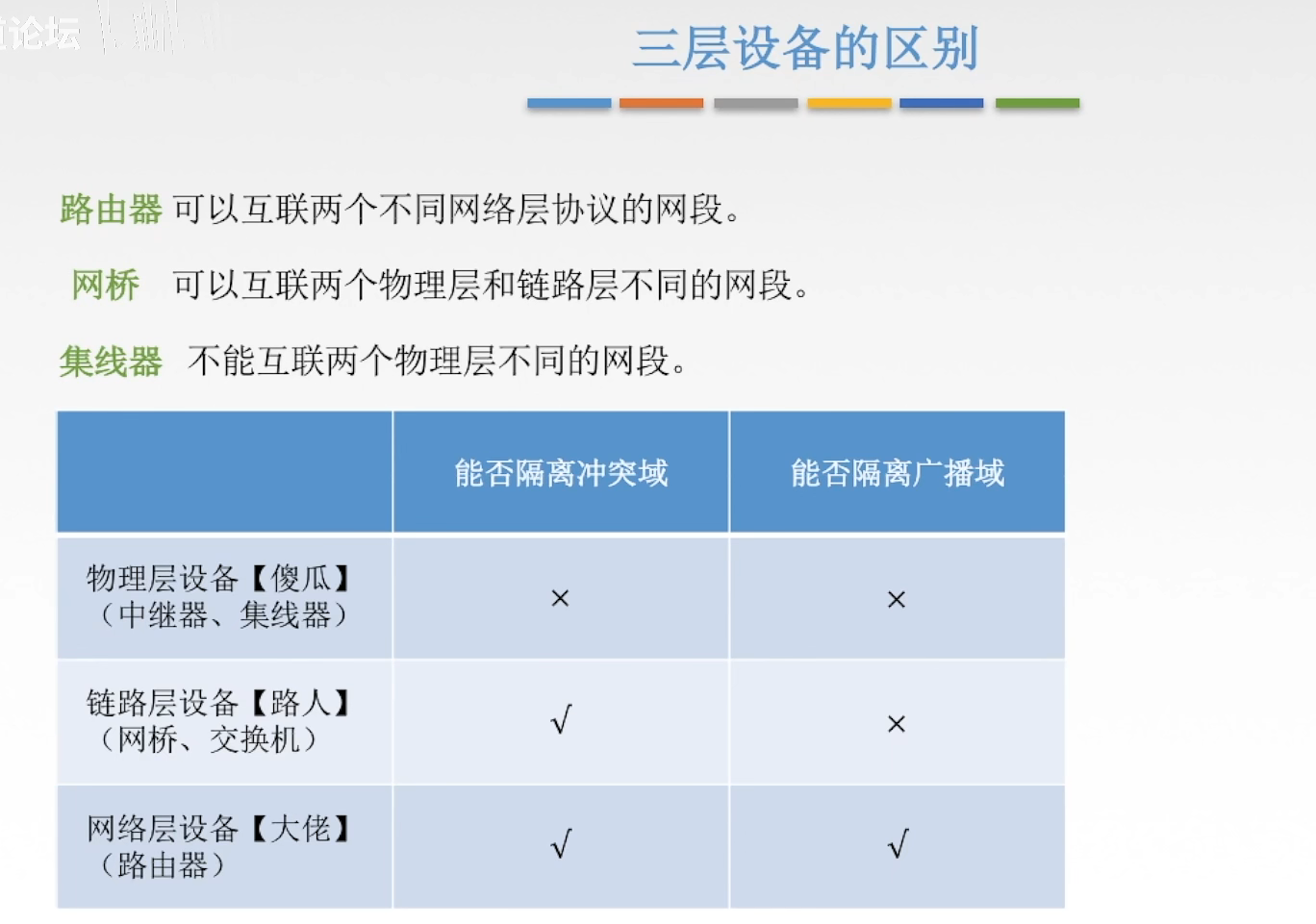
整理BY:Misayaas
内容来自:《线性代数讲义》
行列式
克莱姆法则简单版
若存在方程组$\begin{cases}
a_{11}x_1 + a_{12}x_2= b_1 \\
a_{21}x_1 + a_{22}x_2= b_2\\
\end{cases}$,
可令$\Delta = \begin{vmatrix}
a_{11} & a_{12} \\
a_{21} & a_{22} \\
\end{vmatrix}$,$\Delta_1 = \begin{vmatrix}
b_1 & a_{12} \\
b_2 & a_{22} \\
\end{vmatrix}$,
$\Delta_2 = \begin{vmatrix}
a_{11} & b_1 \\
a_{21} & b_2 \\
\end{vmatrix}$
则对该方程组有一下结论(可以递推更高阶):
若$\Delta \neq 0$,则方程组有唯一的解,$x_1 = \frac{\Delta_1}{\Delta},x_2 = \frac{\Delta_2}{\Delta}$
若$\Delta = 0$,但$\Delta_1,\Delta_2$不全为0,则方程组无解
若$\Delta = \Delta_1 = \Delta_2 =0$,则方程组有无穷多组解
方程组解的结论:
齐次线性方程组必有零解,非齐次方程都是非零解
含有n个未知数的n个方程的齐次线性方程组若有非零解,则它的行列式等于0(充要条件)
行列式基本性质
某两行(列)对应成比例,则行列式的值为0
若行列式的某一行\列拆分成两行(列)元素的和,则行列式可以拆成两个行列式的和
行列式任一行\列的公因子可以提出称为该行列式的因子
两行\列元素交换后,原行列式的值差一个负号
n阶行列式的性质
行列式和它的转置行列式的值相等
两行\列元素交换后,原行列式的值差一个负号
- 两行(列)相等的行列式的值为0
- 行列式可以按任一行(列)展开
行列式任一行\列的公因子可以提出称为该行列式的因子
- 用k乘以行列式的某一行(列),其结果就等于用k去乘这个行列式
将行列式 的任意一行(列)乘以k加到另一方(列)上去,行列式的值不变
行列式任一行(列)的元素与另一行(列)的代数余子式对应的乘积之和为0
反对称
一切奇数阶的反对称行列式都等于0
范德蒙德行列式
$D = \begin{vmatrix}
1 & 1 & \cdots &1\\
x_1 & x_2 & \cdots &x_n\\
x_1^2 & x_2^2 & \cdots &x_n^2\\
\vdots & \vdots & &\vdots\\
x_1^{n-1} & x_2^{n-1}& \cdots &x_n^{n-1}\\
\end{vmatrix} = \prod_{1 \leq i \leq j \leq n}(x_j - x_i)$
矩阵、向量
奇异矩阵
如果|A| $\neq$ 0,则称矩阵A是非异矩阵,如果|A| = 0,则矩阵A是奇异矩阵或退化矩阵
矩阵乘法
结合律:(AB)C = A (BC)
数乘结合律:k(AB)= (kA)B = A(kB)
分配律:A(B + C)= AB + AC
矩阵相乘的行列式:|A$\cdot$B| = |A| $\cdot$ |B|
转置矩阵
$(A^T)^T = A;|A^T| = |A|$
$(A + B)^T = A^T + B^T$
$(kA)^T = kA^T$
$(AB)^T = B^TA^T$
分块矩阵
$A = \begin{vmatrix}
P_{11} & P_{12} \\
P_{21} & P_{22} \\
\end{vmatrix}$,则$A^T = \begin{vmatrix}
P_{11}^T & P_{21}^T \\
P_{12}^T & P_{22}^T \\
\end{vmatrix}$
初等变换和初等矩阵
初等矩阵左(右)乘一个矩阵的结果就是对这个矩阵做相应的初等行(列)变换
推论:
设A为$m \times n$矩阵,r(A) = r,则存在m阶可逆矩阵P和n阶可逆矩阵Q,使得$A = P\Lambda Q$
- 其中$\Lambda = \begin{vmatrix}
E_r & O \\
O & O_{(m -r)\times (n-r)} \\
\end{vmatrix}$
等价
等价关系具有自反性、对称性、传递性,若A和B等价,那么A可以经过有限次初等变换得到B
具有行等价关系的矩阵所对应的线性方程组有相同的解
行梯型矩阵和行简化梯形矩阵
共同点:
零行在最下面
从第一行起,每行第一个非零元素前面的零的个数逐行增加
行简化阶梯型特有:
- 非零行第一个非零元素为1,其所在列其他元素为0
矩阵的秩
矩阵的秩是非零子式的最高次数(宋浩说的最重要)
基础知识:
$0 \leq r(A_{m \times n}) \leq min(m,n)$
$r(A^T) = r(A)$
$r(A) = n \Longleftrightarrow |A| \neq 0 \Longleftrightarrow A非异$
初等变换不改变矩阵的秩
任一满秩矩阵可以经过若干次初等行(列)变换变为单位矩阵
可逆矩阵
AB = BA = E且逆矩阵是唯一的
基本性质:
若A可逆,则$A^{-1}$也可逆,且$(A^{-1})^{-1} = A$,且|$A^{-1}$| = $|A|^{-1}$
若A可逆,则kA也可逆(k$\neq$ 0),且$(kA)^{-1} = k^{-1}A^{-1}$
若A可逆,则$A^T$也可逆,且$(A^T)^{-1} = (A^{-1})^T$
若A、B为同阶可逆矩阵,则AB也可逆,且$(AB)^{-1} = B^{-1}A^{-1}$
推论:
矩阵A可逆的充要条件是:A为满秩矩阵
矩阵A可逆的充要条件是:$|A| \neq 0,且A^{-1} = \frac{1}{|A|} A^*$
伴随矩阵
基本公式是:$AA^\ast = A^\ast A = |A|E$
推论:
设A为n阶方阵($n \geq 2$),则$|A^*| = |A|^{n-1}$
设A为n阶方阵($n \geq 2$),则$(A^\ast) ^\ast= |A|^{n-2}A$
线性组合
给定n维向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_m$和同维向量 $\beta$,如果存在一组数$k_1,k_2,\cdots,k_m$,使得 $\beta = k_1\alpha_1+k_2\alpha_2+\cdots+k_m\alpha_m$,则称 $\beta$ 是向量组A的一个线性组合或称向量 $\beta$ 可由向量组A线性表示
性质:
零向量是任何向量组 $\alpha_1,\alpha_2,\cdots,\alpha_m$ 的线性组合
任何n维向量都可由 $e_1,e_2,\cdots,e_n$ 线性表示,向量组 $e_1,e_2,\cdots,e_n$ 也称为n维基本向量
等价向量组
设有两个向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_m$ 及B:$\beta_1,\beta_2,\cdots,\beta_m$,若A中的每个向量都可由向量组B线性表示,则称向量组A可由向量组B线性表示,若两个向量组A,B可以相互表示,则成这两个向量等价
线性相关和线性无关
定义:(超级无敌重要啊啊啊啊啊)
给定一向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_m$,如果存在不全为零的数 $k_1,k_2,\cdots,k_m$,使得 $k_1\alpha_1+k_2\alpha_2+\cdots+k_m\alpha_m = \theta$,那么称向量组A是线性相关的
如果只有当 $k_1=k_2=\cdots=k_m=0$ 时,上述等式才成立,那么就是线性无关的
线性相关的充要条件是:$x_1\alpha_1+x_2\alpha_2+\cdots+x_m\alpha_m = \theta$($Ax = \theta$) 有非零解
最基本的结论:
一个向量线性相关的充要条件是: $\alpha = \theta$
一个向量线性无关的充要条件是: $\alpha \neq \theta$
包含零向量的向量组是线性相关的
如果一个向量组的部分向量组线性相关,则该向量组也线性相关
如果一个向量组线性无关,则其中任一个部分分量也线性无关
定理:
向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_m$($m \geq 2$)线性相关的充要条件是:向量组A中至少有一个向量可由其余 m-1 个向量线性表示
向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_m$($m \geq 2$)线性无关的充要条件是:其中任何一个向量都不能由其余向量线性表示
设向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_r$ 线性无关,而向量组B:$\alpha_1,\alpha_2,\cdots,\alpha_r,\beta$ 线性相关,则向量 $\beta$ 必可由向量组A线性表示,并且表达式唯一
设向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_r$ 线性无关,则向量组B:$\alpha_1,\alpha_2,\cdots,\alpha_r,\beta$ 线性无关的充分必要条件是向量 $\beta$ 不可能由向量组A线性表示
向量线性相关性与矩阵秩的关系
n维列向量组A:$\alpha_1,\alpha_2,\cdots,\alpha_r$ 线性相关的充要条件是: $r(A) < r$,线性无关的充要条件是: $r(A) = r$
n个n维向量线性无关的充要条件是其行列式不为0
设 $A_{m \times n}$ 的秩 $r(A) = r \leq m$ ,且 A 的某 r 列(行)组成的矩阵含有不等于零的r阶子式,则此 r 列(行)向量线性无关
极大无关组和向量组的秩
极大无关组定理推论:
设 $\alpha_{i_1},\alpha_{i_2},\cdots,\alpha_{i_r}$ 是向量组 $\alpha_1,\alpha_2,\cdots,\alpha_m$ 的一个极大无关组,则向量组 $\alpha_1,\alpha_2,\cdots,\alpha_m$ 中的任一向量可由 $\alpha_{i_1},\alpha_{i_2},\cdots,\alpha_{i_r}$ 线性唯一表示
一个向量组的各个极大无关组所含向量个数相同
向量组和它的极大无关组等价
一个向量组的各个极大无关组是等价的
两个向量组等价的充要条件是:一组的一个极大无关组与另一组的一个极大无关组等价
向量组的秩:
等价的向量组必有相同的秩
任一矩阵的秩与其行秩、列秩相等
秩的重要性质:
$r(A + B) \leq r(A) + r(B)$
$r(AB) \leq min\{r(A),r(B)\}$
若A,B都为n阶方阵,$r(AB) \geq r(A) + r(B) - n$
秩的不等式
$0 \leq r(A) \leq min(m, n)$
$r(kA) = r(A)$
$r(A) = r(A^T) = r(AA^T) = r(A^TA)$
对于$n \times n$矩阵$A$,有 $r(A^n) = r(A^{n+1})$
$max(r(A),r(B)) \leq r(A,B) \leq r(A) + r(B)$
$r(A + B) \leq r(A, B)$
$r(AB) \leq min(r(A), r(B))$
$r(\left(\begin{matrix}
A & O \\
O & B \\
\end{matrix}\right)) = r(A) + r(B)$
$r(A) + r(B) \leq r(\left(\begin{matrix}
A & O \\
C & B \\
\end{matrix}\right)) \leq r(A) + r(B) + r(C)$
$r(AB) \geq r(A) + r(B) - n$
若 $AB = O$,则 $r(A) + r(B) \leq n$,其中n是A的列数
线性代数组解的结构
线性方程组的可解性
线性方程组有解的充要条件是:系数矩阵A的秩等于增广矩阵B的秩
- $r(A) = r(B) = n$ 时,方程组有唯一解
- $r(A) = r(B) \leq n$ 时,方程组有无穷多组解
- $r(A) \neq r(B)$ 时,方程组无解
齐次方程组解的结构
若 $\alpha_1,\alpha_2$ 是方程组 $Ax = \theta$ 的解,则其线性组合 $k_1\alpha_1 + k_2\alpha_2$ 也是该方程组的解
设 $A \in R^ { m \times n}$,若 $r(A) = n$ 时,则 $Ax = \theta$ 只有零解;若 $r(A) < n$,则 $Ax = \theta$ 有非零解
若齐次方程有非零解,则该方程组的基础解系并不唯一
若齐次方程组的系数矩阵A的秩为r,则其基础解系的向量个数为$n-r$
非齐次方程组解的结构
若 $A\eta = b$($b \neq \theta$),则 $Ax = b$ 的通解为 $\eta + \alpha$
- 其中 $\alpha$ 为 $Ax = \theta$ 的解(齐次方程的解)
- 若 $Ax = \theta$ 的基础解系为 $\alpha_1,\alpha_2,\cdots,\alpha_r$,则 $A\eta = b$ 的通解为$\eta + k_1\alpha_1 + k_2\alpha_2 + \cdots + k_r\alpha_r$
矩阵的特征值线性无关和特征向量
相似矩阵
对于同阶方阵A与B,如果存在可逆矩阵P,使得 $B = P^{-1}AP$,则称A相似于B,记为 $A \sim B$,P称为A到B的相似变换矩阵
相似矩阵性质:
若 $A \sim B$,则|A| = |B|,从而A和B可逆性相同
若 $A \sim B$,且A或B可逆,则 $A^{-1} \sim B^{-1}$
若 $A \sim B$,则 $A^n \sim B^n$,$kA \sim kB$
若 $A \sim B$,则 $f(A) \sim f(B)$,其中 $f(x) = \alpha_nx^n + \alpha_{n-1}x^{n-1}+\cdots +\alpha_1x^1+\alpha_0x^0$ 为任意多项式
相似矩阵具有相同的特征多项式,从而有相同的特征值
相似矩阵具有相同的迹和行列式
特征值和特征向量
特征多项式是:$|\lambda E - A| = 0$
设方阵A有特征值 $\lambda$,$\xi_1,\xi_2$ 是属于$\lambda$ 的特征向量,则它们的任意不等于零向量的线性组合 $\eta = k_1\xi_1 + k_2\xi_2$ 仍是属于 $\lambda$ 的特征向量
若 $f(x)$ 为x的多项式,矩阵A有特征值 $\lambda$,则 $f(A)$ 有特征值 $f(\lambda)$
若n阶可逆方阵A的所有特征值为 $\lambda_1,\cdots,\lambda_n$(包含相同的特征值),则 $\lambda_i \neq 0$,且矩阵 $A^{-1}$ 的特征值为 $\lambda_1^{-1},\cdots,\lambda_n^{-1}$
若n阶矩阵A的特征值为 $\lambda_1,\cdots,\lambda_n$
- 主对角线之和等于特征值之和:$tr(A) = \sum_{i = 1}^n \lambda_i$
- 行列式的值等于特征值的乘积:$|A| = \prod_{i = 1}^n \lambda_i$
设A是一个块对角矩阵,$A =
\left(
\begin{matrix}
A_1 & & & \\
& A_2 & & \\
& & \ddots&\\
& & & A_m
\end{matrix}
\right)$
则A的特征多项式是 $A_1,A_2,\cdots,A_m$ 的特征多项式的乘积,于是 $A_1,A_2,\cdots,A_m$ 的所有特征值就是A的所有特征值
m阶方阵AB与n阶方阵BA具有相同的非零特征值,且 $tr(AB) = tr(BA)$
属于不同特征值的特征向量线性无关
若 $\lambda_1,\lambda_2,\cdots,\lambda_n$ 是矩阵A的不同特征值,而A的属于 $\lambda_i$ 的线性无关的特征向量为 $\alpha_{i1},\alpha_{i2},\cdots,\alpha_{is_i}$,则向量组 $\alpha_{11},\cdots,\alpha_{1s_i},\alpha_{21},\cdots,\alpha_{2s_i},\cdots,\alpha_{m1},\cdots,\alpha_{ms_m}$ 线性无关
设 $\lambda_0$ 是n阶方阵A的k重特征值,则A的属于特征值 $\lambda_0$ 的线性无关的特征向量的个数不超过k
矩阵可对角化的条件
n阶矩阵可对角化的充要条件是:有n个线性无关的特征向量,且对角矩阵的主对角线由特征值组成,相似变换矩阵由属于相应特征值的特征向量构成
n阶方阵可对角化的充要条件是:每个 $k_i$ 重特征值 $\lambda_i$ 对应的特征矩阵 $|\lambda_iE - A|$ 的秩为 $n-k_i$
向量内积
- $(\alpha,\beta)=(\beta,\alpha)$
- $(k\alpha,\beta)=k(\alpha,\beta)$
- $(\alpha+\gamma,\beta)=(\alpha,\beta) + (\gamma,\beta)$
- $(\alpha,\alpha)\geq0;(\alpha,\alpha)=0当且仅当\alpha = \theta$
若 $(\alpha,\beta)=0$,则称 $\alpha$ 和 $\beta$ 正交或垂直
正交向量和正交矩阵
若实矩阵满足 $A^TA=E$,则称A为正交矩阵
- 若A,B是同阶的正交矩阵,那么AB也是正交矩阵
- E也为正交矩阵
性质:
正交向量组必线性无关
对于方阵A,下面一些条件互为等价:
A为正交矩阵
$A^T=A^{-1}$
$AA^T=E$
A的列向量构成标准正交列向量组
A的行向量构成标准正交行向量组
设A是n阶正交矩阵,$\lambda$ 是A的特征值,$\alpha$ 为n维列向量
实对称矩阵对角化
实对称矩阵一定可以对角化
性质:
实对称矩阵的特征值均是实数
实对称矩阵的属于不同特征值的特征向量相互正交
设有实n维单位列向量 $\beta$,则比能找到 n-1 个向量与 $\beta$ 一起构成由n个向量组成的标准正交向量组
若A是实对称矩阵,则存在同阶的正交矩阵P使得 $P^TAP$ 是实对角矩阵,从而实对称矩阵可以对角化
实二次型
线性变换
定义:$x = cy$(宋浩说x一定写在前面,我觉得怎么不用)
线性变换系数行列式为$|P| = \begin{vmatrix}
c_{11} & c_{12} & \cdots &c_{1n}\\
x_{21} & x_{22} & \cdots &x_{2n}\\
\vdots & \vdots & &\vdots\\
x_{n1} & x_{n2}& \cdots &x_{nn}\\
\end{vmatrix}$
合同
定义:同阶方阵A、B之间存在一个可逆矩阵P,使得$B = P^TA\:P$,那么称为A合同于B
合同关系是一个等价关系
二次型化简
矩阵表示:$f(x_1,x_2,\cdots,x_n) = x^TA\:x$
定理:
存在非退化的线性变换将实二次型化为标准形,且平方项系数可以任意次序排列
存在可逆矩阵将实对称矩阵合同变换为实对角矩阵,且对角元素可以任意次序排列
化简方法:
正交矩阵法
求解矩阵A的特征方程$|\lambda E-A| = 0$
求出基础解系
将标准正交化的特征向量作为列构成正交矩阵$P= \left(\begin{matrix}
p_{11} & p_{12} & p_{13}\\
p_{21} & p_{22} & p_{23}\\
p_{31} & p_{32}& p_{33}\\
\end{matrix}\right)$
得到线性变换$\begin{cases}
x_1 = p_{11}y_1 + p_{12}y_2 + p_{13}y_3\\
x_2 = p_{21}y_1 + p_{22}y_2 + p_{23}y_3\\
x_3 = p_{31}y_1 + p_{32}y_2 + p_{33}y_3
\end{cases}$
配方法
式中有非零平方项比如$a_{11}x_1^2$:将式中所有含$x_1$的项配成一个平方项$a_{11}(x_{11} + \frac{a_12}{a_11}x_2 + \cdots + \frac{a_{1n}}{a11}x_n)^2$,并令非退化线性变换为$\begin{cases}
y_1 = x_1 + \frac{a_{12}}{a_{11}}x_2 + \cdots + \frac{a_{1n}}{a_{11}}x_n\\
y_2 = x_2\\
\cdots \cdots \\
y_n = x_n
\end{cases}$
即可把原式化为不含$x_1$和$y_1$的交叉项的式子
式中无非零平方项:可以用一个线性变换配出平方项,例如$2a_{12}x_{1}x_{2}$,则作如下非退化线性变换
$\begin{cases}
x_1 = y_1 + y_2\\
x_2 = y_1 - y_2\\
x_3 = y_3 \\
\cdots \cdots \\
x_n = y_n
\end{cases}$,然后再按情况一处理
合同变换法
设二次型矩阵为$A = \left(\begin{matrix}
a_{11} & a_{12} & \cdots &a_{1n}\\
a_{12} & a_{22} & \cdots &a_{2n}\\
\vdots & \vdots & &\vdots\\
a_{n1} & a_{n2}& \cdots &a_{nn}\\
\end{matrix}\right)$
对矩阵$B = \left(\begin{matrix}
A \\
E \\
\end{matrix}\right)$ 做一次初等列变换后接着做一次对应的初等行变换,重复这种做法,直到得到$\left(\begin{matrix}
\Lambda \\
P \\
\end{matrix}\right)$,然后P的用法参考正交矩阵法
二次型的规范形
惯性定理:存在非退化的线性变换将实二次型化为实规范形 $z_1^2 + \cdots + z_p^2 - z_{p + 1}^2 - \cdots - z_r^2$ ;存在实可逆矩阵将实对称矩阵合同变换为 $diag(E_p,-E_{r-p},O_{n-r})$,其中r是二次型矩阵的秩
推论:
- 实二次型矩阵A的正特征值个数为正惯性指数,负特征值个数为负惯性指数,非零特征值个数为二次型的秩
正定二次型
若A为n阶是实对称矩阵,则下列条件互为等价:
半正定等情况类似
A为正定矩阵
A的特征值为正
A的正惯性指数为n
A的各阶顺序主子式都为正
线性空间与线性变换
数环
属于集合 $R$ 的任意两个数的和、差、积仍属于 $R$,则称这个集合 $R$ 为数环
数域
若 $K$ 是至少含有两个互异数的数环,且其中任何两个数之商仍属于 $K$ ,则称这个集合 $K$ 为数域
线性空间
设 $V$ 是一个非空集合,$K$ 是一个属于,V满足以下两个条件:
在 $V$ 中定义一个封闭的加法运算,即当 $x,y \in V$ 时,有唯一的 $z = x + y \in V$,且满足:
$x + y = y + x$
$x + (y + z) = (x + y) + z$
存在零元素 $0 \in V$,对 $V$ 中任意元素 $x$,都有 $x + 0 = x$
存在负元素:对任一元素 $x \in V$,存在一个元素 $y \in V$,使得 $x + y = 0$,称 $y$ 为 $x$ 的负元素,记为 $-x$,即 $x + (-x) = 0$
在 $V$ 中定义一个封闭的数乘运算,即当 $x \in V,\lambda \in K$ 时,有唯一的 $\lambda x \in V$,且满足:
$(\lambda + \mu)x = \lambda x + \mu x$
$\lambda(x + y) = \lambda x + \lambda y$
$\lambda(\mu x) = (\lambda \mu)x$
$1\cdot x = x$
我们称 $V$ 是属于 $K$ 上的线性空间,记作 $V(K)$
性质:
线性空间的零元素是唯一的
线性空间中任一元素的负元是唯一的
设 $0,1,-1,\lambda \in K,x,-x,0 \in V$,则有:
只含一个元素的线性空间称为零空间
基与坐标
设 $V$ 是数域 $K$ 上的线性空间,
如果在 $V$ 中可以找到任意多个线性无关的向量,则称 $V$ 是无限维线性空间
如果存在有限多个向量 $a_1, a_2, \cdots, a_n \in V$,满足:
$a_1, a_2, \cdots, a_n$ 线性无关
$V$ 中任一向量都可由 $a_1, a_2, \cdots, a_n$ 线性表示
则称 $V$ 是有限维线性空间,称 $a_1, a_2, \cdots, a_n$ 是V的一组基(基底),$a_i$ 叫第 $i$ 个基向量,基向量的个数 $n$ 称为线性空间的维数,记为 $dim(V) = n$,并称 $V$ 是 $n$ 维线性空间
定理:
设 $a_1, a_2, \cdots, a_n$ 是 $n$ 维线性空间 $V$ 的一组基,对任意 $a \in V$,$a$ 可以唯一地由这一组基线性表出
设 $a_1, a_2, \cdots, a_n$ 是 $n$ 维线性空间 $V$ 的一组基,对任意 $a \in V$,若有一组有序数 $x_1,x_2,\cdots,x_n$ 使得 $a$可表示为 $a = x_1a_1 + x_2a_2 + \cdots + x_na_n$,这组有序数就称为向量 $a$ 在基 $a_1, a_2, \cdots, a_n$ 下的坐标,记为 $x = (x_1,x_2,\cdots,x_n)$ 或 $x = (x_1,x_2,\cdots,x_n)^T$
基变换和坐标变换
设 $\alpha_1, \alpha_2, \cdots, \alpha_n$ 和 $\beta_1,\beta_2,\cdots,\beta_n$ 是 $n$ 维线性空间 $V$ 的两组基,并且 $(\beta_1,\beta_2,\cdots,\beta_n) = (\alpha_1, \alpha_2, \cdots, \alpha_n)P$,若 $V$ 中任意元素 $\alpha$ 在这两组基下的坐标分别是 $(x_1,x_2,\cdots,x_n)$ 和 $(y_1,y_2,\cdots,y_n)$
- 存在 $(y_1,y_2,\cdots,y_n)^T = P^{-1}(x_1,x_2,\cdots,x_n)^T$
子空间
线性空间 $V$ 的一个非空子集 $W$ 是 $V$ 的子空间的充要条件:
对任意 $\alpha , \beta \in W$,有 $\alpha +\beta \in W$,即对加法封闭
对任意 $\alpha \in W,\lambda \in K$,有 $\lambda \alpha \in W$,即对数乘封闭
线性空间 $V$ 的一个非空子集 $W$ 是 $V$ 的子空间的充要条件:
- 对任意的 $\alpha , \beta \in W,\lambda,\mu \in K$,有 $\lambda \alpha +\mu \beta \in W$
齐次方程组的全体解向量是 $R^n$ 的一个非空子集 $W$ ,则 $W$ 是 $R^n$ 的一个子空间,该齐次方程组的任一组基础解系是 $W$ 的一组基,若这个方程组系数矩阵的秩为 $r$ ,则 $dim(W) = n -r$
子空间的交与和
数域 $K$ 上线性空间 $V$ 的两个子空间 $W_1,W_2$的交与和仍是$V$ 的子空间
若 $W_1,W_2$ 是线性空间 $V$ 的两个有限维子空间,则 $dim(W_1) + dim(W_2) = dim(W_1 + W_2) + dim(W_1 \cap W_2 )$
子空间的直和
若 $W_1 + W_2$ 中任一向量都只能唯一地表示为子空间 $W_1$ 的一个向量与子空间 $W_2$ 的一个向量和,则称 $W_1 + W_2$ 是直和,记为 $W_1 \oplus W_2$
定理:
$W_1 + W_2$ 是直和的充要条件:$W_1 \cap W_2 = \{0\}$
$W_1 + W_2$ 是直和的充要条件:$dim(W_1 + W_2) = dim(W_1) + dim(W_2)$
若 $W_1,W_2,\cdots W_m$ 是线性空间 $V$ 的子空间,若
$W_1 + W_2 +\cdots +W_m = V$
$W_1 \cap W_2 = \{0\},(W_1 + W_2) \cap W_3 = \{0\}, \cdots ,(W_1 + W_2 + \cdots + W_{m-1}) \cap W_m = \{0\}$
则 $V$ 是 $W_1,W_2,\cdots W_m$ 的直和
线性变换
如果 $V_1$ 到 $V_2$ 的映射满足:$T(\lambda \alpha +\mu \beta) = \lambda T \alpha + \mu T \beta$,则称 $T$ 为 $V_1$ 到 $V_2$ 的线性映射
其中 $\alpha,\beta \in V_1,\lambda \in K$
在 $V_1 = V_2 = V$ 时,称这个 $T$ 为 $V$ 上的线性变换
线性映射性质:
$T0 = 0$
对任意的 $\alpha_1,\alpha_2,\cdots,\alpha_m \in V_1$,有 $T(K_1\alpha_1 + k_2\alpha_2 + \cdots k_m\alpha_m) = k_1T\alpha_1 + k_2T\alpha_2 + \cdots + k_mT\alpha_m$
若 $\alpha_1,\alpha_2,\cdots,\alpha_m$ 线性相关,则 $T\alpha_1,T\alpha_2,\cdots,T\alpha_m$ 也线性相关
特殊的线性变换:
像空间和核空间
若 $V_1,V_2$ 都是数域 $K$ 上线性空间,有线性映射$T:V_1 \rightarrow V_2$
定理:
- 线性映射的像空间和核空间是线性子空间
线性变换的矩阵表示
定义:
设线性变换的矩阵为 $A$,则存在 $(T\varepsilon_1,T\varepsilon_2,\cdots,T\varepsilon_n) = (\varepsilon_1,\varepsilon_2,\cdots,\varepsilon_n)A$
- $A$ 的第 $i$ 个列向量是 $T\varepsilon_i$ 在基 $\varepsilon_1,\varepsilon_2,\cdots,\varepsilon_n$ 下的坐标
设由基底 $\varepsilon_1,\varepsilon_2,\cdots,\varepsilon_n$ 到 $\omega_1,\omega_2,\cdots,\omega_n$ 的过度矩阵为 $P$,也就是 $(\omega_1,\omega_2,\cdots,\omega_n) = (\varepsilon_1,\varepsilon_2,\cdots,\varepsilon_n)P$,而且线性变换的矩阵分别为 $A,B$,那么有以下结论:
定理:
对 $V$ 的两个线性变换 $T_1,T_2$,有 $T_1 \varepsilon_i = T_2\varepsilon_i$,则 $T_1 = T_2$
$A \sim B$ 的充要条件:它们是 $n$ 维的线性空间 $V$ 上的某个线性变换 $T$ 在不同基底下的矩阵
线性变换的特征值和特征向量
特征子空间:线性变换 $T$ 对应于特征值 $\lambda$ 的子空间 $V_{\lambda} = \{\xi \in V:T\xi = \lambda \xi\}$
- 包括对应于 $\lambda$ 的所有特征向量和零向量
最简表示:线性变换 $T$ 在某组基上的矩阵为对角矩阵
定理:
有限维线性空间上的线性变换的特征值和特征多项式与所选基底无关
设 $\lambda_1,\lambda_2,\cdots,\lambda_s$ 是线性变换 $T$ 的 $s$ 个互异的特征值,$\xi_i$ 是属于特征值 $\lambda_i$ 的特征向量,则 $\xi_1,\xi_2,\cdots,\xi_s$ 线性无关
$n$ 维线性空间上的一个线性变换 $T$ 有最简表示的充要条件: $T$ 有 $n$ 个线性无关的特征向量
若 $\xi_1,\xi_2,\cdots,\xi_s$ 和 $\nu_1,\nu_1,\cdots,\nu_s$ 分别是线性变换 $T$ 不同特征值的线性无关的特征向量,则 $\xi_1,\xi_2,\cdots,\xi_s$;$\nu_1,\nu_1,\cdots,\nu_s$ 线性无关
若 $\lambda_0$ 是线性变换 $T$ 的 $s$ 重特征值,则属于 $\lambda_0$ 的特征向量中,线性无关的最大组包含的向量个数不超过 $s$