数据通路
CPU
CPU任务
取指令:从存储器读取指令
解释指令:对指令进行译码,以确认所要求的动作
取数据:指令的执行可能要求从存储区或I/O模块中读取数据
处理数据:指令的执行可能要求对数据完成某些算数或逻辑运算
写数据:执行的结果可能要求写数到存储器或I/O模块
CPU需求
CPU需要一些小容量的内部存储器
CPU需要在指令周期中临时保存指令和数据
CPU需要记录当前所执行指令的位置,以便知道从何处得到下一条指令
控制和状态寄存器
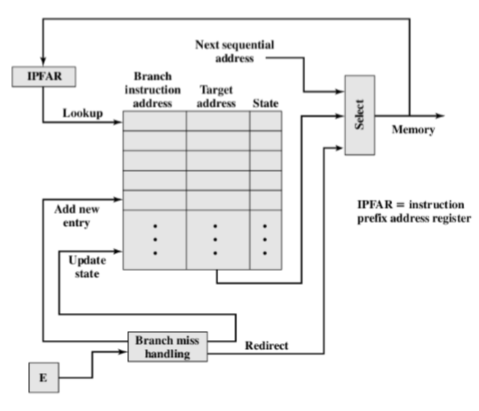
存储地址寄存器:MAR
MAR直接到地址总线
不仅仅是存储指令的地址,而是可以存储所有的数据地址
存储缓冲(数据)寄存器:MBR/MDR
包含要写入内存的数据字或最近读取的数据字
MBR直接连接到数据总线
可以直接访问MBR和用户可见寄存器
程序计数器:PC
处理器在每次取指令后就更新PC
分支或跳过指令也会修改PC的内容
指令寄存器:IR
- 获取的指令呗加载到IR中,在IR中分析操作码和操作数说明符
程序状态字:PSW
一个或一组寄存器包含状态信息
Sign:最后一次算术运算结果的符号位
Zero:结果为0时设置
Carry:有进位或出位则设置
Equal:设置逻辑比较结果是否相等
Overflow:表示算术溢出
Interupt:启用或禁用中断
Supervisor:指示处理器是以Supervisor模式还是用户模式执行
数据流
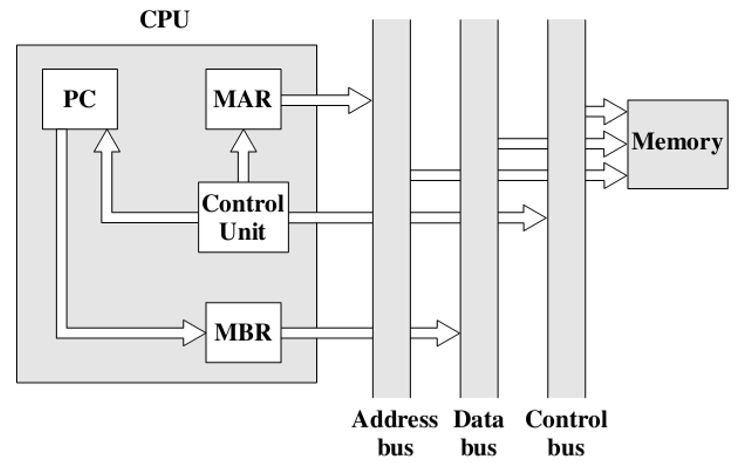
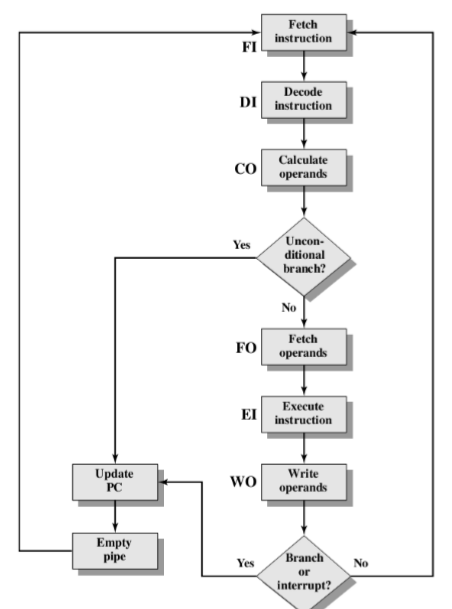
取指周期
- 把下一条指令地址放到MAR中,然后交给内存
控制单元设置控制线的信号,如果控制线设置为相应信号,内存会始终监听信号线
- 当读到读信号时,则会从MAR中读出一个地址,然后取出数据给数据总线
将数据从数据总线读到MBR中,然后拷贝到IR中
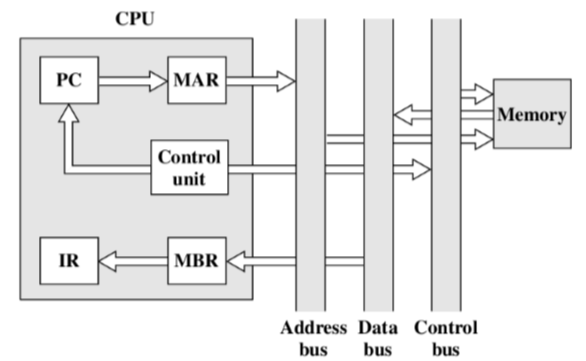
间址周期
MBR中是地址,将地址拷贝到MAR中
控制单元发送读请求,内从从MAR中进行拉取后,从内存中取出来,返给MBR
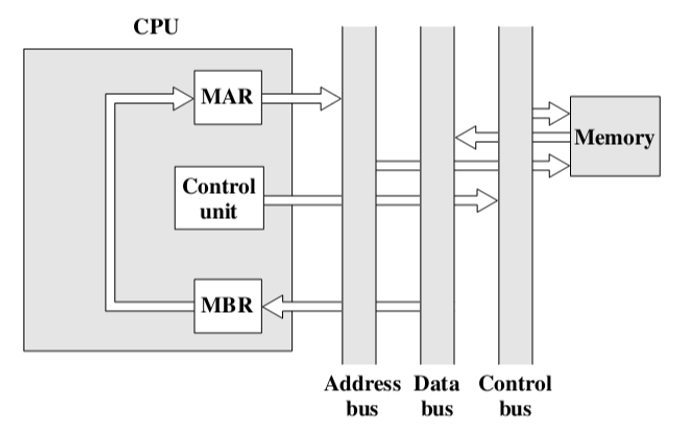
中断周期
控制单元会先告诉主存有写操作
之后控制单元会为MAR指定一个写入的位置
指令流水线
指令流水线:一条指令的处理过程分成若干个阶段,每个阶段由相应的功能部件完成
两阶段方法
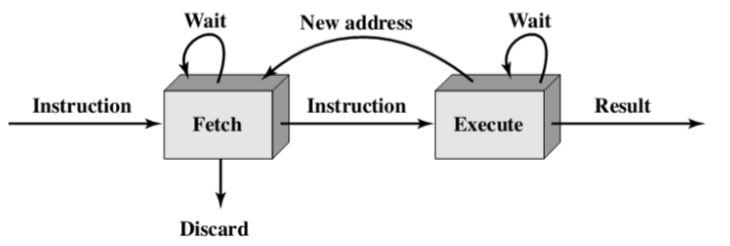
将指令处理分为两个阶段:取指令、执行指令
- 在当前指令的执行期间取下一条指令

问题:
执行时间一般长于取指时间
可能出现内存访问冲突
条件分支指令使得待取的下一条指令的地址是未知的
六阶段方法
为了进一步的加速,流水线必须有更多阶段,各个阶段所需要的时间几乎是相等的
取指令(FI):读下一条指令到缓冲器
译码指令(DI):确定操作码和操作数指定符
计算操作数(CO):计算每个源操作数的有效地址
取操作数(FO):从存储器取出每个操作数,寄存器中的操作数不用取
执行指令(EI):完成指定的操作,若有指定的目的操作数的位置,则将结果写入此位置
写操作数(WO):将结果存入存储器
不是所有指令都包含6个阶段
- LOAD指令不需要WO阶段
不是所有阶段都能并行完成
- FI、FO、WO都涉及存储器访问
限制:
若6个阶段不全是相等的时间,则会在各个流水阶段涉及某种等待
条件分支指令可以是使多个指令获取无效
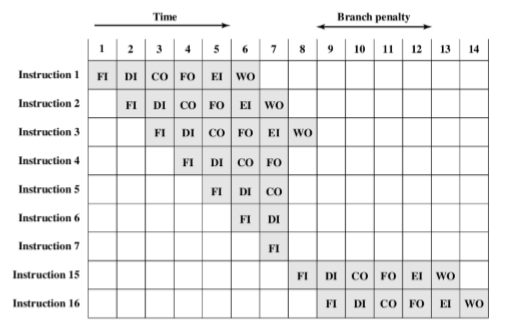
- 如果调到了15号指令,则之前的所有的数据都被“浪费掉”
问题:
最多的时候会同时处理6件事情,所以需要遵守6个任务中时间最长的任务所需时间
微指令之间存在时间间隔,所以6个指令加起来的运算时间要大于原来一次计算完
可能出现内存冲突

流水线性能
假设:
$t_i$:流水线第 $i$ 段的电路延迟时间
$t_m$: 最大段延迟(通过耗时最长段的延迟)
$k$:指令流水线段数
$d$:锁存延时(数据和信号从上一段到下一段所需的段间锁存接收时间)
周期时间:$t = max[t_i] + d = t_m + d$
令 $T_{k,n}$ 为 $k$ 阶段流水线执行所有 $n$ 条指令所需的总时间,则:
$T_{k,n} = [k + (n - 1)] t$
加速比:$S_k = \frac{T_{1,n}}{T_{k,n}} = \frac{nkt}{[k + (n - 1)]t} = \frac{nk}{k + (n - 1)} = \frac{n}{1 + \frac{n - 1}{k}}$
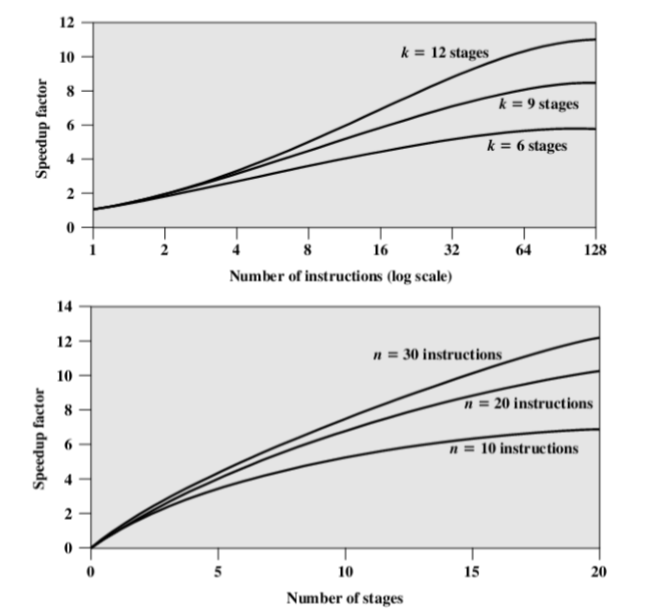
误解:流水线中的阶段数越多,执行速度越快
会造成指令间隔变多,间隔浪费的时间也会增加
会造成指令控制比较复杂
原因:
在管道的每个阶段,将数据从一个缓冲区移动到另一个缓冲区以及执行各种准备和传递功能都会涉及一些开销
处理内存和寄存器依赖项以及优化管道使用所需的控制逻辑量随着阶段数的增加而大大增加
冒险(Hazard)
在某些情况下,指令流水线会阻塞或停顿(stall),导致后续指令无法正确执行
类型:
结构冒险(硬件资源冲突)
数据冒险(数据依赖性)
控制冒险
结构冒险
已进入流水线的不同指令在同一时刻访问相同的硬件资源
解决:使用多个不同的硬件资源,或者分时使用同一个硬件资源
- 可以分时复用:前半段读出,后半段写入

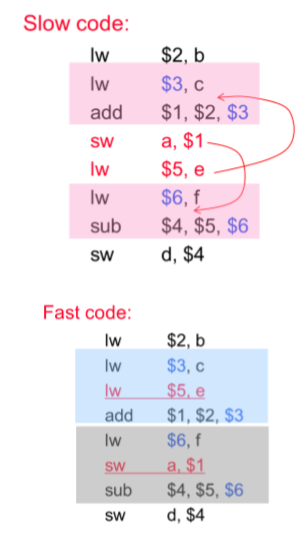
数据冒险
未生成指令所需要的数据
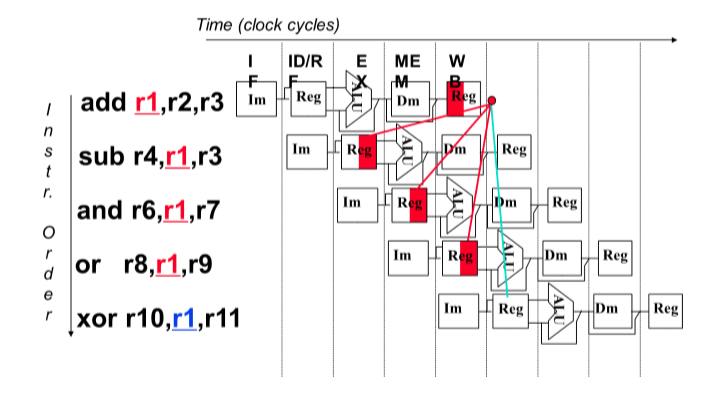
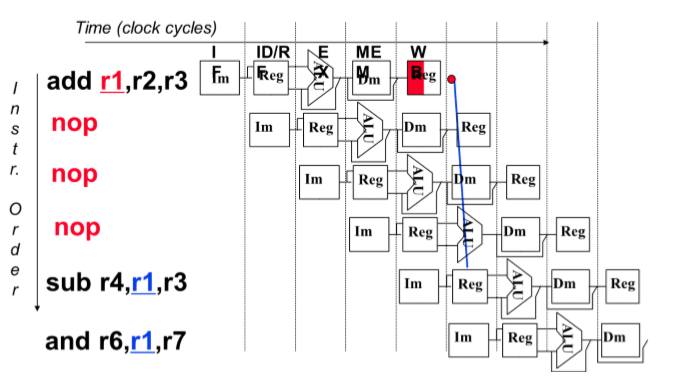
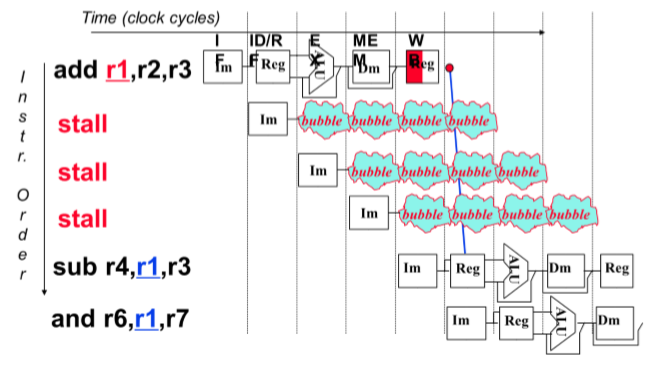
解决:
- 插入nop指令(空操作)
- 插入bubble(等待)
- 转发(forwarding)/ 旁路(bypassing)
- 旁路:添加一根线来获取目标数据
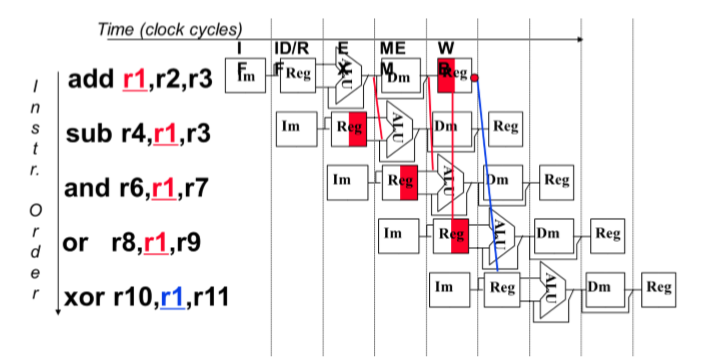
- 交换指令顺序

控制冒险
指令执行顺序被更改
- 转移、中断、异常、调用/返回
解决:
取多条指令
多个指令流:复制流水线的开始部分,并允许流水线同时取这两条指令,使用两个指令流
预取多支目标:识别出一个条件分支指令时,除了取此份之指令之后的指令外,分支目标处的指令也被取来
循环缓冲器:由流水线指令取指阶段维护的一个小的但极高速的存储器,含有n条最近顺序取来的指令
分支预测
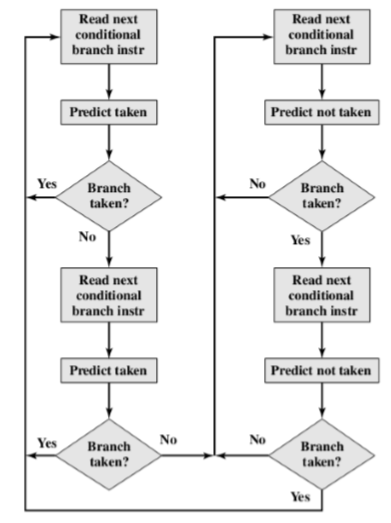
静态预测:
预测绝不发生
预测总是发生
依操作码预测
动态预测:
发生/不发生切换
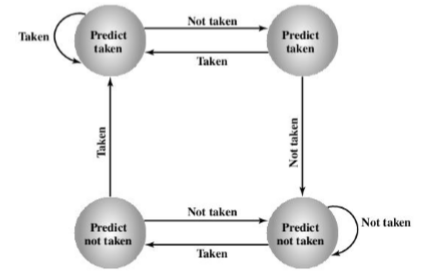
转移历史表