内部存储器
基础
存储器由一定数量的单元构成,每个单元可以被唯一标识,每个单元都有存储一个数值的能力
地址:单元的唯一标识符
地址空间:可唯一标识的单元总数
寻址空间:存储在每个单元中的信息的位数
- 大多数存储器是字节寻址的
半导体存储器
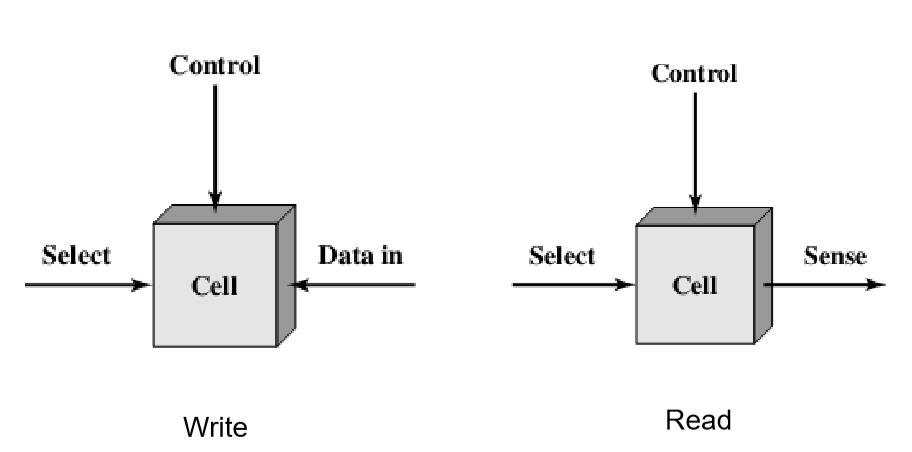
位元(memory cell):半导体存储器的基本元件,用于存储1位数据
呈现两种稳态(或半稳态):分别表示二进制的0和1
能够至少被写入数据一次:用来设置状态
能够被读取来获取状态信息
半导体存储器类别:
| 类型 | 种类 | 可擦性 | 写机制 | 易失性 |
|---|---|---|---|---|
| 随机存取存储器(RAM) | 读-写存储器 | 电可擦除,字节级 | 电 | 易失 |
| 只读存储器(ROM) | 只读存储器 | 不可能 | 掩膜 | 非易失 |
| 可编程ROM(PROM) | 只读存储器 | 不可能 | 电 | 非易失 |
| 可擦除PROM(EPROM) | 主要进行读操作的存储器 | 紫外线可擦除,芯片级 | 电 | 非易失 |
| 电可擦除PROM(EEPROM) | 主要进行读操作的存储器 | 电可擦除,字节级 | 电 | 非易失 |
| 快闪存储器 | 主要进行读操作的存储器 | 电可擦除,块级 | 电 | 非易失 |
随机存取存储器(RAM)
特性:
可以简单快速地进行读/写操作
易失的(Volatile)
类型:
DRAM(动态RAM):
在电容器上用电容充电的方式存储数据
电容器有无电荷分别代表二进制1和0
需要周期地充电刷新以维护数据存储
电容器有漏电的自然趋势
有一个阈值来确定电荷是解释为1还是0
刷新是异步刷新
传统DRAM是异步的
处理器向内存提供地址和控制信号,表示内存中特定单元的一组数据应该被读出或写入DRAM
DRAM执行各种内部功能,如激活行和列地址线的高电容,读取数据,以及通过输出缓冲将数据输出,处理器只能等待这段延迟,即存取时间
延时后,DRAM才写入或读取数据

SRAM(静态RAM):
使用传统触发器、逻辑门配置来存储二进制值
使用与处理器相同的逻辑元件
只要有电源,就可以一直维持数据

DRAM和SRAM对比
相同:
- 易失性:两者都要求电源持续供电才能保持位值
不同:
DRAM具有更简单、更小的位元,但要求能支持刷新的电路
DRAM密度更高,价格更低
SRAM通常更快
DRAM倾向满足大容量存储器的需求,SRAM一般用于高速缓存,SRAM用于主存
高级DRAM架构
传统的DRAM芯片受到其内部架构与处理器内存总线接口的限制
类型:
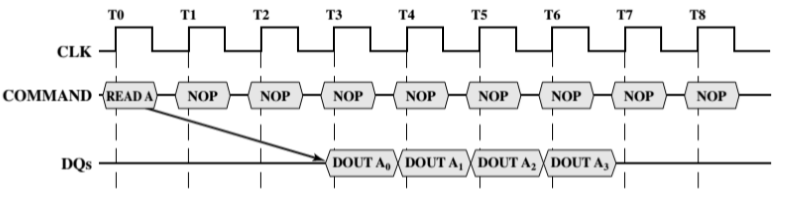
SDRAM(同步DRAM):
SDRAM与处理器的数据交互同步与外部的时钟信号,并且以处理器/存储器总线的最高速度运行,不需要插入等待状态
由于SDRAM随系统时钟及时移动数据,CPU直到数据何时准备好,控制器可以完成其他工作
异步是需要再次沟通的,而同步是减少一些交互,确定具体的交互时间(延迟时间)
数据读写是在时钟周期的上升点进行
DDR SDRAM(双速率SDRAM):
每个时钟周期发送两次数据,一次在时钟脉冲的上升沿,一次在下降沿
DDR $\rightarrow$ DDR2 $\rightarrow$ DDR3 $\rightarrow$ DDR4
增加操作频率
增加预取缓冲区
只读存储器(ROM)
特性:
非易失性:不要求供电来维持数据
只可读:但不能写入新数据
应用:
- 微程序设计、库子系统、系统程序、函数表
问题:
无出错处理机会
用户无法写入数据
- 唯一的数据写入机会在出厂时完成
可编程ROM(PROM)
PROM提供了灵活性和方便性,在大批量生产领域仍具有吸引力
特性:
非易失性
只能写入一次
写过程是用电信号执行
需要特殊设备来完成写或“编程”过程
可擦除可编程“只读”存储器(EPROM)
EPROM比PROM更贵,但有可多次改写的优点
特性:
光擦除:在写操作前将封装芯片暴露在紫外线下
所有的存储单元都便会相同的初始状态
每次擦除需要约20分钟
电写入
电可擦除可编程“只读”存储器(EEPROM)
与EPROM对比,EEPROM更贵,且密度低,支持小容量芯片
特性:
可以随时写入而不删除之前的内容
只更新寻址到的一个或多个字节
写操作每字节需要几百微秒
快闪存储器
价格和功能介于EPROM和EEPROM之间
特性:
电可擦除
- 与EEPROM相同
擦除时间为几秒
- 优于EPROM,不如EEPROM
可以在块级擦除,不能在字节级擦除
- 优于EPROM,不如EEPROM
从位元到主存
寻址单元
寻址单元由若干相同地址的位元组成
每个寻址单元内的数据不能进行局部修改,而是整体修改
寻址模式:
字节(Byte):常用
字(Word)

存储阵列
存储阵列由大量寻址单元组成
选中就是对行和列进行加电,然后同时被加电的地方被选中
随机访问:先读取地址,然后找到行和列,然后选中,所以无论是什么单元,都是一样的访问时间
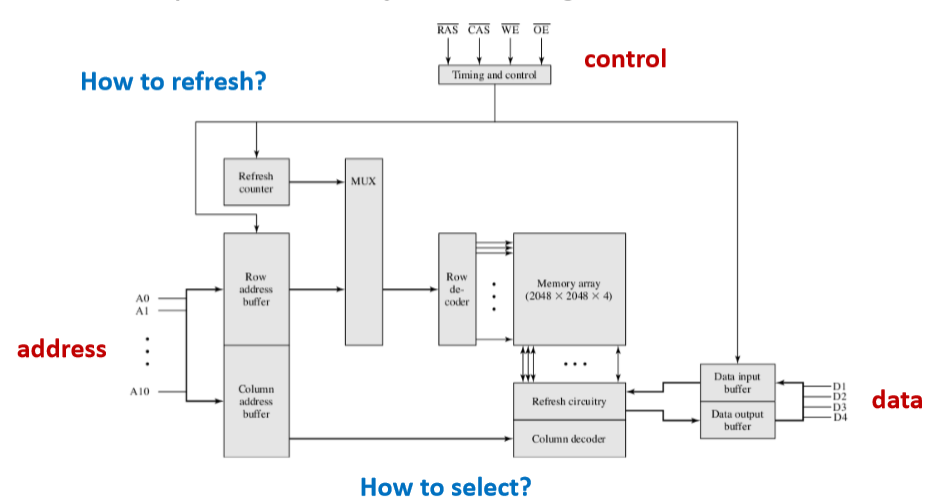
如何寻址
地址译码器:

如何刷新
存储周期:读/写一次所耗费的时间
- 某行刷新一次的时间也等于一个存取周期
刷新间隔:所有存储单元都刷新一遍的时间
刷新类型:
集中式刷新(Centralized refresh)
停止读写操作,并刷新每一行
- 刷新时无法操作内存
分散式刷新(Decentralized refresh)
在每个存储周期中,当读写操作完成时进行刷新
- 会增加每个存储周期的时间
异步刷新(Asynchronous refresh)
每一行各自以64ms间隔刷新(按时间切割)
- 效率高
芯片
芯片引脚:
Address:A0-A19
Data:D0-D7
Vcc:电源
Vss:地线
CE:芯片允许引脚
Vpp:程序电压
WE:写允许
OE:读允许
RAS:行地址选通
CAS:列地址选通

模块组织
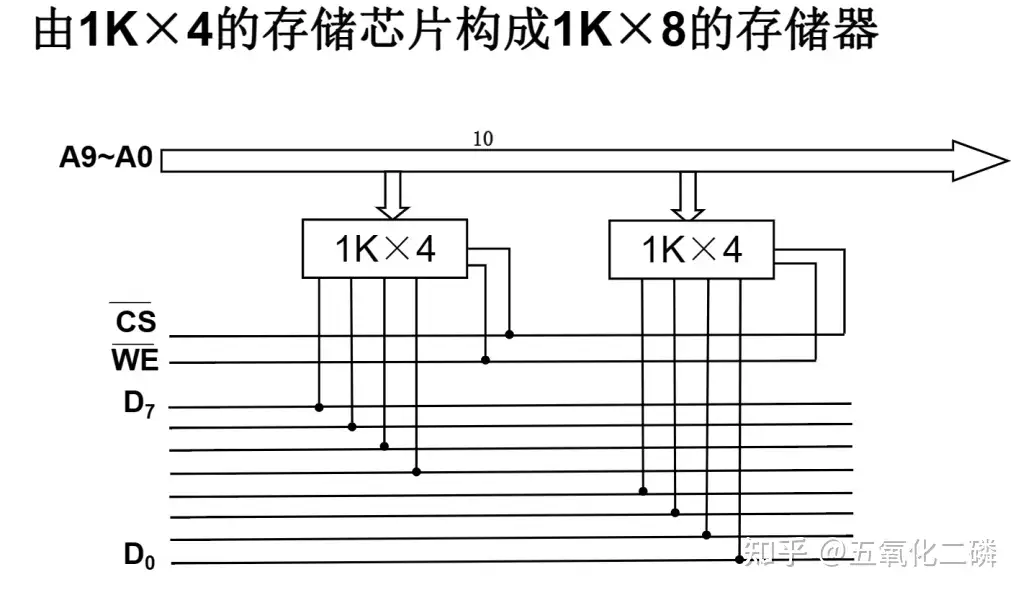
位扩展
地址线不变,数据线增加
使用8个4K*1bit的芯片组成4K*8bit的存储器
字扩展
地址线增加,数据线不变
使用4个16K*8bit的芯片组成64K*8bit的存储器
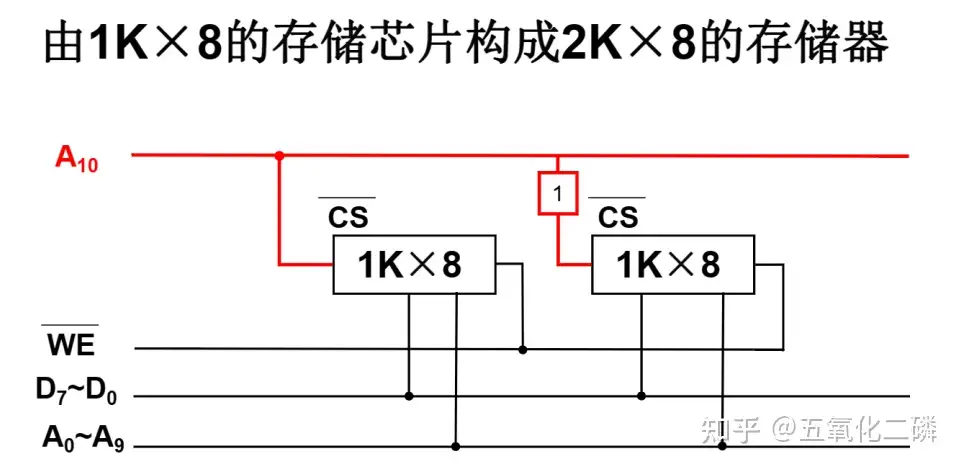
字位扩展
地址线增加,数据线增加
使用8个16K*4bit的芯片组成64K*8bit的存储器

高速缓冲存储器Cache
CPU的速度比内存的速度块,且两者的差距不断扩大,导致出现内存墙
Cache的基本思路
在使用主存之余,添加一块小而快的Cache,存放主存中部分信息的副本
- Cache位于CPU和主存之间,可以集成在CPU内部或作为主板上的一个模块
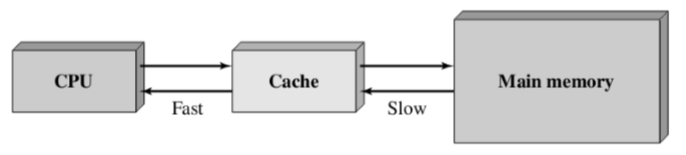
Cache运行流程
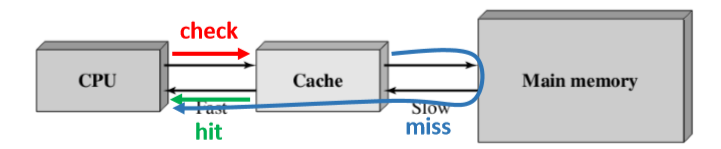
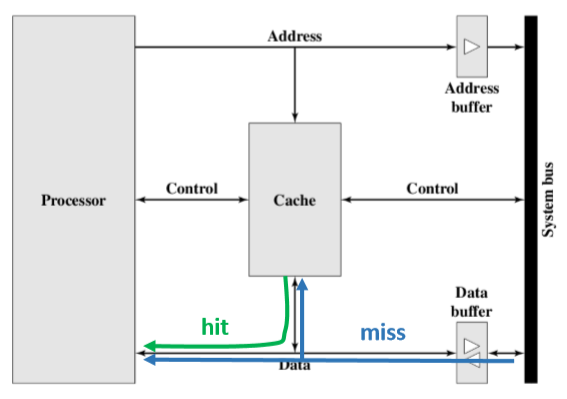
检查:当CPU试图访问主存中的某个字时,会首先检查这个字是否在Cache中
检查后分两种情况:
命中hit:如果在Cache则把这个字传送给CPU
未命中miss:如果不在Cache,则将主存中包含这个字固定大小的块读入Cache中,然后再从Cache传送该字给CPU
无论如何Cache都会首先访问Cache
Cache通过标记tags来标识其内容在主存中的对应位置
- 将Cache中每一行的标记和目标地址的标记进行比较,如果有相同即为命中
局部性原理
定义:处理器频繁访问主存中相同位置或相邻存储位置的现象
类型:
时间局部性:在相对较短的时间周期内,重复访问特定的信息
也就是相同位置的信息
1
2
3
4int factorial = 1;
for (int i = 2; i <= n; i++) {
factorial = factorial * i;
}
空间局部性:在相对较短的时间周期内,访问相邻存储位置的数据
1
2
3for (int i = 0; i < num; i++) {
score[i] = final[i] * 0.4 + midterm[i] * 3 + assign[i] * 0.2 + activity[i] * 0.1;
}- 顺序局部性:线性排列并访问
由于时间局部性,将未命中的数据再返回给CPU的同时存放在Cache中,以便再次访问命中
由于空间局部性,将包含所访问的字的块存储到Cache中,以便在访问相邻数据时命中
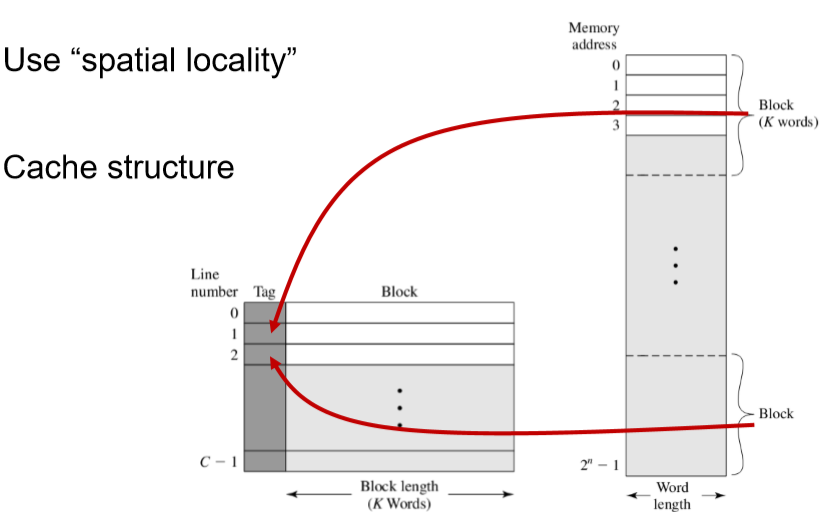
搬一个块的时间要比一次次搬块内每个单元的时间要快,因此Cache能节省时间
平均访问时间
设P是命中率,$T_c$是Cache的访问时间,$T_m$是主存的访问时间
使用Cache的平均访问时间:$T_a = p \times T_c + (1-P) \times (T_c + T_m) = T_c + (1 - P) \times T_m$
命中率P越大,$T_c$越小,效果越好
如果想要$T_a < T_m$,必须要求$P > \frac{T_c}{T_m}$
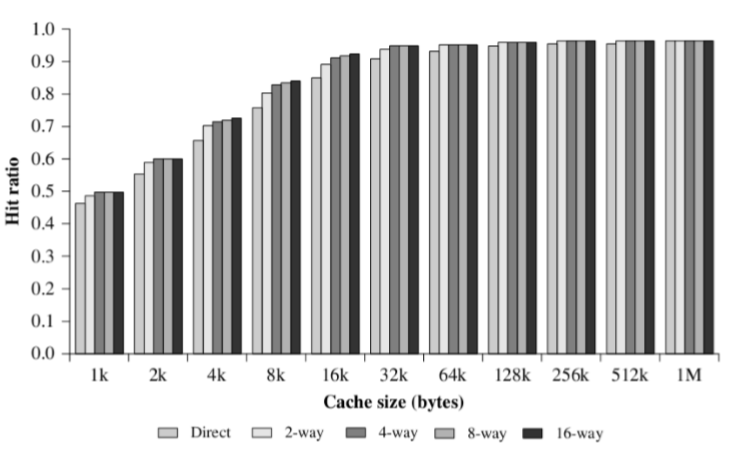
Cache容量
扩大Cache容量后果:
增大命中率P
增加Cache的开销和访问时间$T_c$
- 随着块的增大,P增长会放缓,因为过大就不满足局部性原理了
映射功能
实现主存块到Cache行的映射
映射方式的选择会影响Cache的组织结构
直接映射
全关联映射
组关联映射
Cache和主存结构
Cache
一行:tag + 行 + 字
一共m个块,也就是m行
tag是主存储器的一部分,用来识别当前储存的是哪一块
主存:字长,每一块(k字)
直接映射
将主存中的每个块映射到一个固定可用的Cache行中,适合大容量的Cache

- $Cache行号 = 主存储器块号\: \% \:Cache行数$
主存储器地址:
| 标记 | Cache行号 | 块内地址 |
|---|---|---|
标记:地址中最高的n位,区分映射到同一行的不同块
$n = log_2M - log_2C$
- M为块数,C为Cache行数
为了成本,要用尽可能少的位置存储tag
优点:简单、快速映射、快速检查
缺点:两个块被重复使用的话有可能出现抖动的现象
全关联映射
一个内存块可以装入Cache的任意一行,适合容量较小的Cache
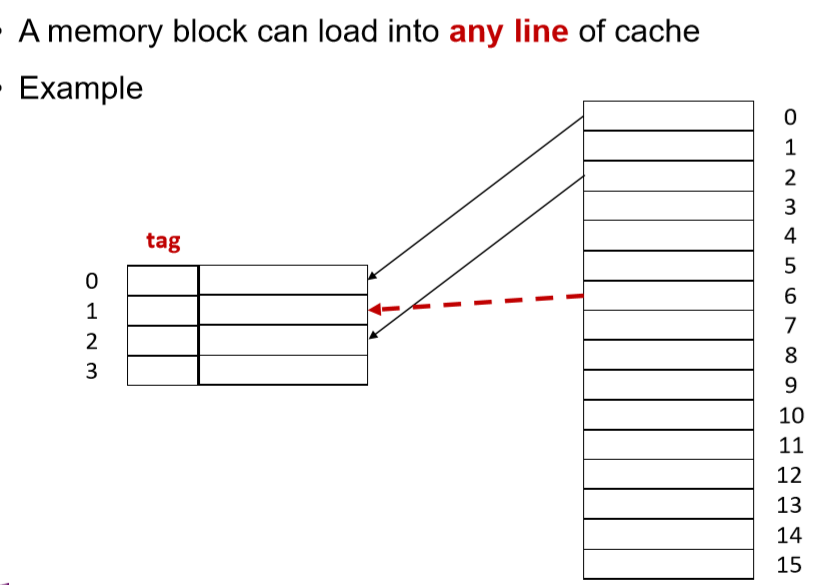
主存储器地址:
| 标记(块号) | 字(块内地址) |
|---|---|
优点:避免抖动
缺点:实现起来比较复杂,搜索代价大,即检查的时候需要去访问Cache每一行
组关联映射
Cache分为若干组,每一组包含相同数量的行,每个主存块被映射到固定组的任意一行,面向不同容量的Cache做了折中
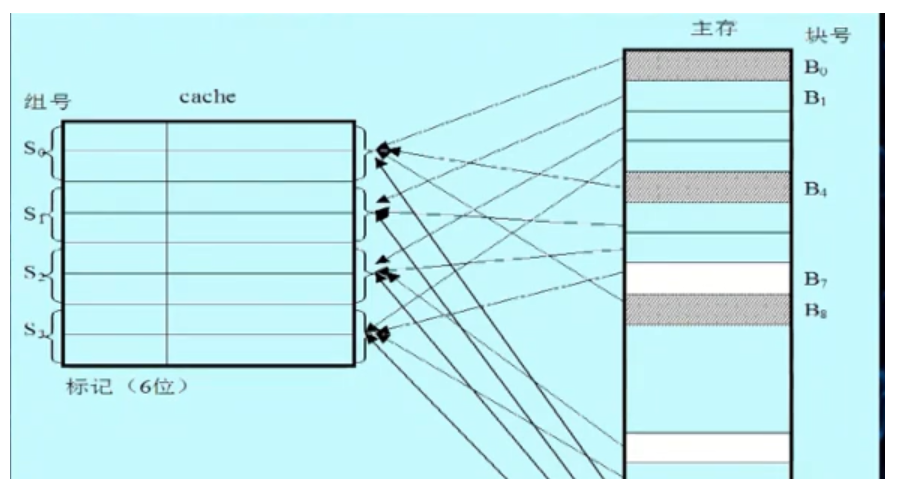
- $Cache组号 = 主存块号\: \% \:组数$
K - 路组关联映射:K是每一组的行数
K=1则等价于直接映射
K=Cache行数则等价于全关联映射
主存储器地址:
| 标记 | Cache组号 | 块内地址 |
|---|---|---|
标记:地址中最高的n位,区分映射到同一组的不同块
$n = log_2M - log_2S$
- M为块数,C为组数
三种映射方式对比
关联度:一个主存块映射到Cache中可能存放的位置个数
直接映射:1
全关联映射:Cache行数
全关联映射:每组的行数
关联度越低,则命中率越低、判断是否命中的时间越短、标记所占额外空间开销越小
替换算法
最近最少使用算法(LRU)
替换在Cache中最长时间未被访问的数据块
- 可以设计一个USE位,未被访问则加1,被访问则置0,替换USE位最大的行
先进先出算法(FIFO)
替换在Cache中停留时间最长的数据块
最不经常使用算法(LFU)
替换Cache中被访问次数最少的数据块
- 每行设置一个计数器
随机替换算法(Random)
随机替换Cache中的数据块
写策略
如果没被修改,则该数据块可以直接被替换掉
如果被修改,则在替换掉该数据块之前,必须将修改后的数据块写回到主存对应位置
缓存命中时写策略
写直达
所有写操作同时对Cache和主存进行
优点:确保主存中的数据总是和Cache中的数据一致
缺点:产生大量的主存访问,减慢写操作
写回法
先更新Cache中的数据,当Cache中某个数据块被替换,如果它被修改了,才被写回主存
利用脏位或使用位表示是否被修改
优点:减少访问主存的次数
缺点:部分主存数据可能不是最新的(未发生替换但需要读主存的场景)
缓存未命中写策略
写不分配:
直接将数据写入主存,无需读入Cache,通常搭配写直达
优点:避免Cache和主存数据不一致
写分配:
将数据所在的块读入Cache后,在Cache中更新内容,通常搭配写回法
优点:减少写内存次数
行大小
随着行大小的逐步增大,Cache命中率会增加
- 空间局部性
行大小较大后,继续增加行大小,Cache命中率会下降
- 频繁替换
行太小,行数太多反时间局部性
行太大,行数太少反空间局部性
Cache数目
一级
将Cache与处理器置于同一芯片
减少处理器在外部总线上的活动,从而减少了执行时间
多级
当$L_1$未命中时,减少处理器对总线上DRAM或ROM的访问
使用单独的数据路径,代替系统总线在$L_2$缓存和处理器之间传输数据,部分处理器将$L_2$ Cache结合到处理器芯片上
统一
更高的命中率,在获取指令和数据的负载之间自动进行平衡
只需设计和实现一个Cache
分立
- 消除Cache在指令的取值/译码单元和执行单元之间的竞争,在任何基于指令的流水线的设计中都是重要的